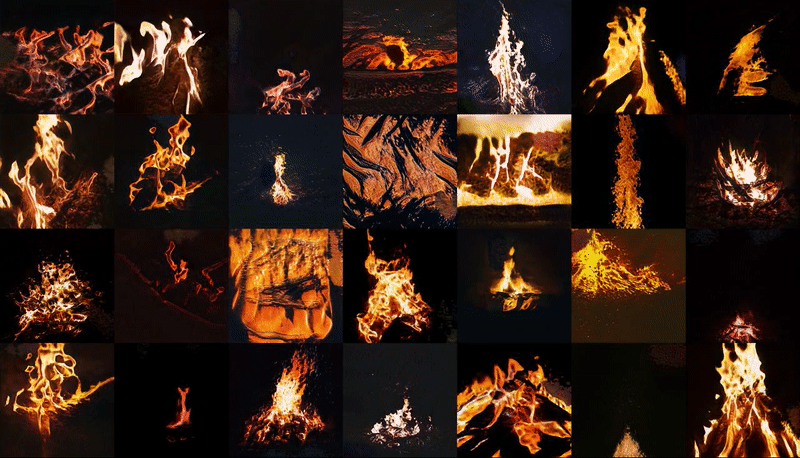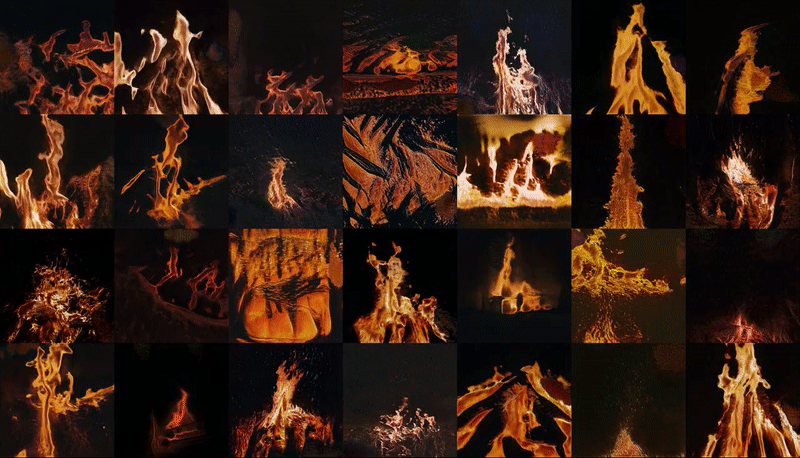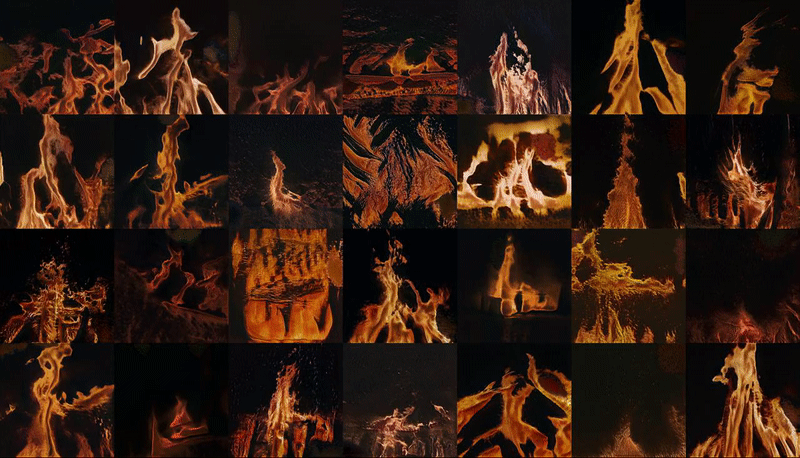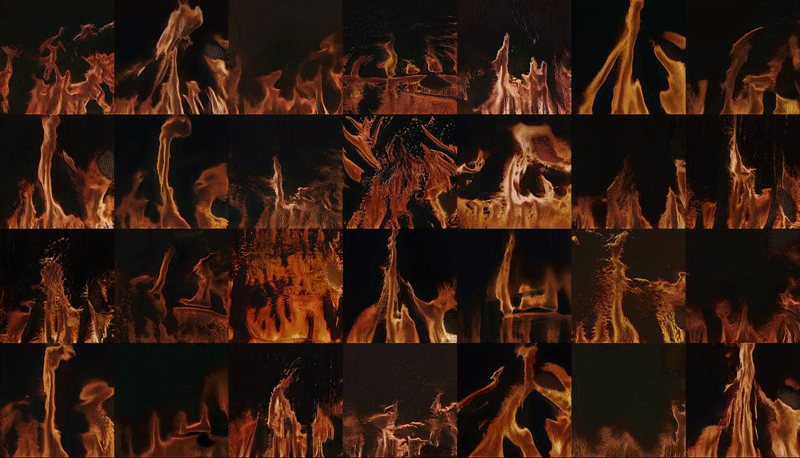
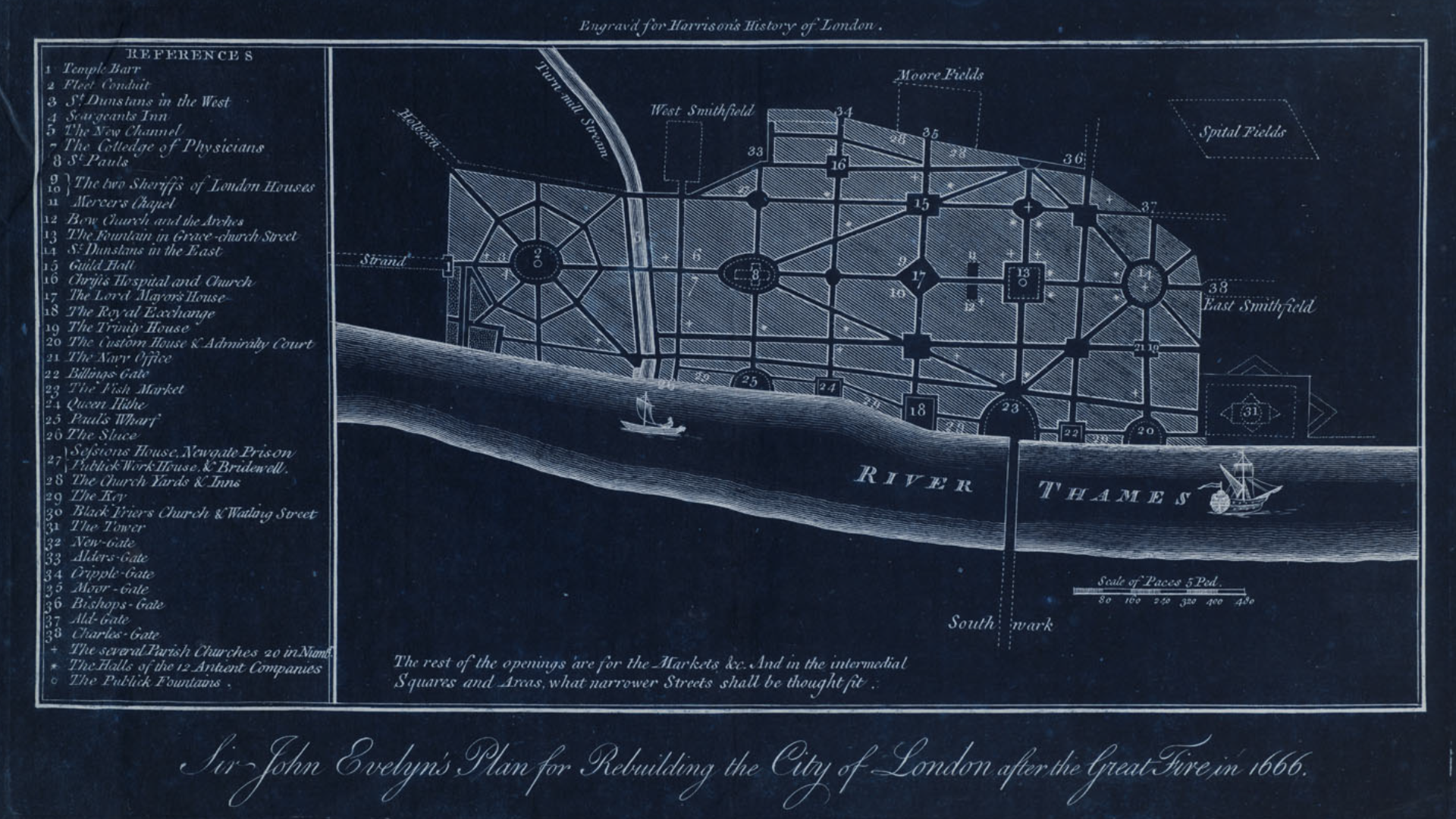
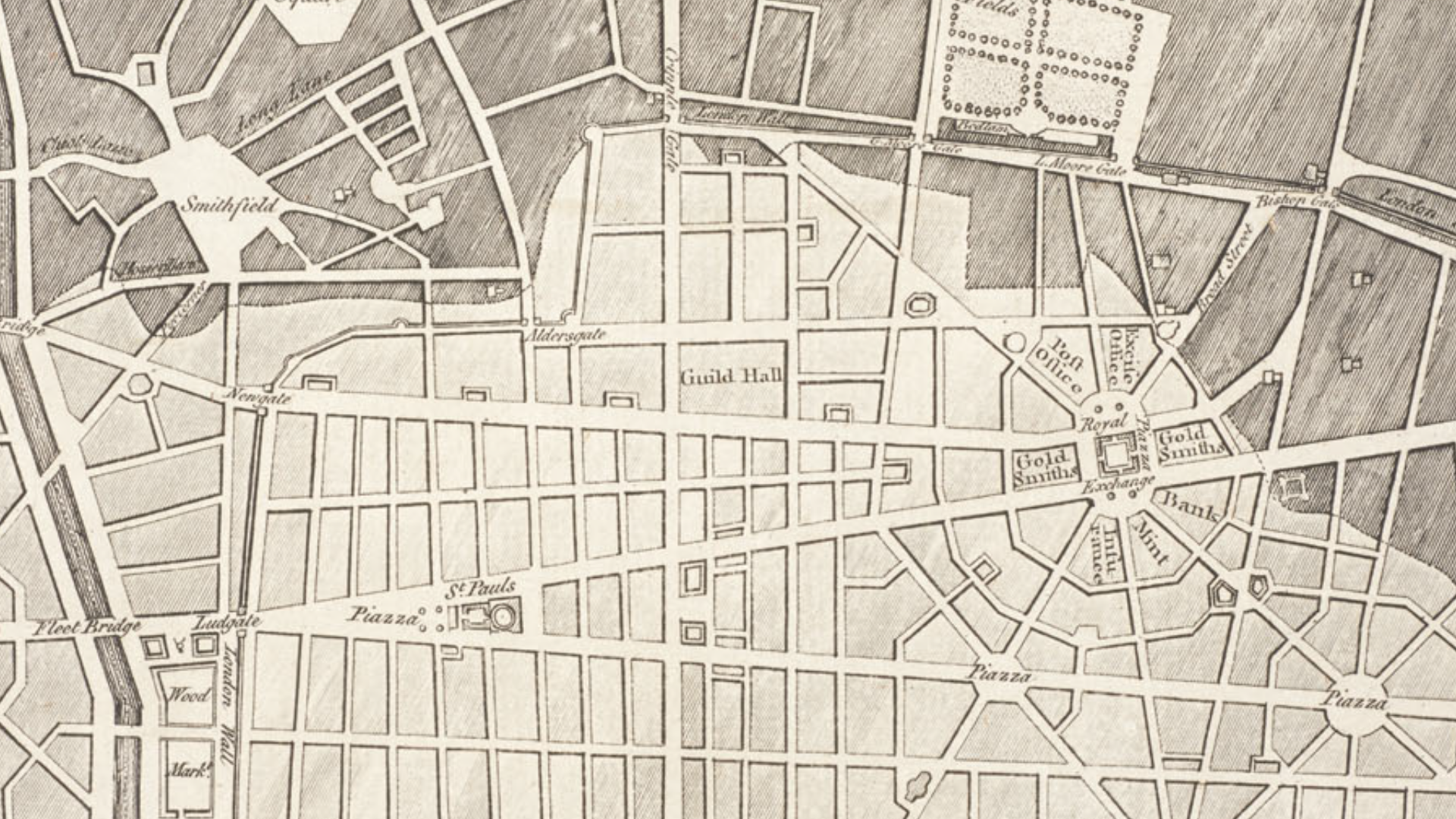
↑ ImageNet, the internet's canonical image database for machine learning and data training, is currently undergoing 'maintenance' after having being ethically compromised as a result of its increasingly questionable stratification of images depicting people.
Although allegedly unrelated to Trevor Paglen and Kate Crawford's 'ImageNet Roulette' project bringing attention to these politically problematic classifications later in 2019, ImageNet remains unavailable for general use. While other image archives are still available, I decided instead to manually and directly save the images I was looking for from Flickr: the hosting site where most of ImageNet's images are actually sourced, and an archive produced before automatic categorisation and therefore largely free from machine-learnt ethics.
Snipping and saving as many images as possible in the period of my laptop's battery life, I built my own synonym set (synset) for images of fire: a job that would previously have been the collective effort of a remote crowd-sourced community working for single pence at a time to classify data and images into online databases. Wondering what exactly my computer and its networks thinks fire looks like, I inputted my own synset into a machine learning training model, processed through a remote GPU - in the cloud but very much on the ground.
This training process, which cost approximately $10, was paid for with the equivalent credit that I personally earned working on various human intelligence tasks (HITs) for the crowd-sourcing marketplace Amazon Mechanical Turk over a period of days. This 30 second latent space walk is therefore a representation of the time, money and labour that accumulated towards the human/computer generation of new, future fires. It implicates computer hardwares, battery lives, energy consumption by both humans and machines. Ultimately, it may feed back into the data-world as images of fires that could well but do not actually exist.